最近一直在做数据统计相关的工作,主要是用 Spark 分析一些关键词在微信中的传播行为。这篇博客记录一下学习的过程。
资源参数调优
使用公司的 Spark 平台计算时,num_executors 设置的 1,导致每个任务需要跑 8 个多小时。num_executors=10 时仅需要 1 小时,num_executors=20 时需要 30 分钟。继续调整 num_executors=100 executor_cores=4 后需要 10 分钟。这是由于参数设置不当导致资源没有充分使用,跑任务任务浪费大量时间。
进行调优需要先大致了解 Spark 的基本运行原理:
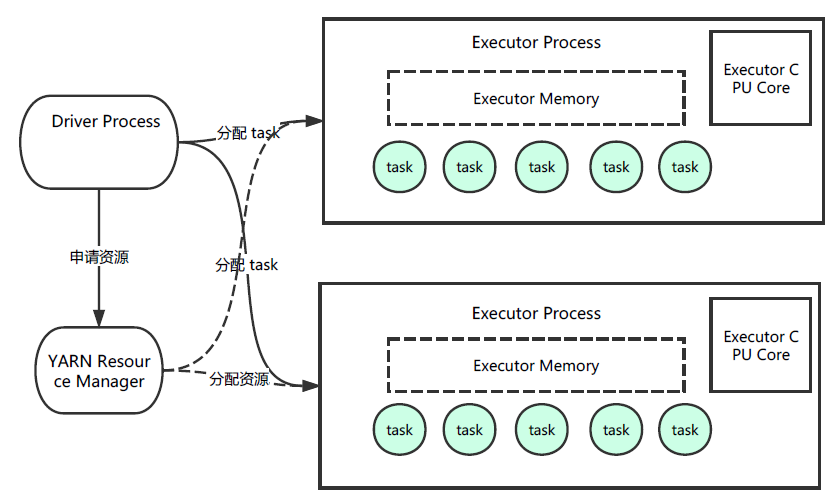
num_executors 是执行器的个数,executor_cores 是执行器中 CPU 的个数。经过实践,设置为下列参数比较合适。
num_executors :每个 Spark 作业运行一般设置 50-100 个左右的 executor 进程比较合适
exucutor-memory:每个 executor 进程设置 4G-8G
executor_cores:决定每个 Executor 进程并行执行 task 线程的能力
driver-memory:1G 左右
代码调优
1、对多次使用的 RDD 进行持久化
var rdd = sc.textFile(“file:///d:/one_day_index.txt”).cache()
cache() 方法使用非序列化的的方式将 RDD 中的数据全部持久化到内存中
2、避免使用 Shuffer 类算子
Shuffer 是把分布在多个节点上的同一个 Key 的数据拉取到同一个节点上,进行聚合或 Join 等操作。如 ReduceByKey 或 Join 等操作。
3、使用 Kryo 优化序列化性能
Kryo 比 Java 自带的序列化库性能要高 10 倍左右。
理解 flatMap
一篇文章分词后有 [文章编号,词 1,词 2,词 3…] 这样的数据,需要生成 [文章编号,词 1] [文章编号,词 2] [文章编号,词 3] ,以便后面对相同的词进行 Reduce,变为 [词 1,文章编号 1,文章编号 2…]。相当于倒排一次。
统计函数 processLineToPair 输入为 [三元组,词 1,词 2,词 3…],输出为 Array[(String, DocObj)],担心的是这样返回在 RDD 里数据只有一行,但经过 flapMap 后就变为了 RDD[(String, DocObj)],变为了多行保存在 RDD 中。
flatMap 的返回是一对多或一对零,而 Map 是一对一。
理解 reduceByKey
reduceByKey 的输入和输出是一样的,经过 flapMap 后返回的 RDD 是有 Key:Value 的概念,所以可以默认去 ByKey 进行 Reduce。reduceByKey 的对象只能是 PairRDD。当需要把一个普通的 RDD 转为 PairRDD 时间,可以调用 map() 函数来实现,传递进 map() 的函数需要返回键值对或者二元元组,二元元组会隐式转换为 PairRDD。
base64 编解码
base64 是把 3 个 8-bit 字节转换为 4 个 6-bit 字节的编码方式,Scala 中使用下面的方式
import org.apache.commons.codec.binary.Base64
Base64.decodeBase64(encode_uin)
Option 的使用
Option 可以包在返回值外面,相当于多了一个异常码。返回为 none 则异常,返回为 Some 则正常。一般和 flapMap 结合使用。
SimpleModPartitioner 对结果进行分区
对数据进行 reduce 的时候可以指定保存结果的分区数,可以节省一步的 Shuffle。
rdd_hash_index.reduceByKey(new SimpleModPartitioner(2000), (v1, v2)
=> reduceMergeWord(v1, v2))
注意 rdd_hash_index 的 KEY 必须是数字才可以正确地 HASH
任务重跑时删除文件夹
1、设置为直接覆盖文件路径,spark.hadoop.validateOutputSpecs 这种可能会导致以前的文件删除不完全。
2、通过 spark 自带的 hadoopconf 方式删除
SparkSQL 相关使用
SparkSQL 是在 DataFrame 的接口基础上使用的。
RDD 是分布式的 Java 对象的集合,DataFrame 是分布式的 Row 对象的集合。
DataFrame 转化为 DataSet df.as[ElementType]
DataSet 转化为 DataFrame ds.toDF()
简单的 SParkSQL 使用示例如下:
val spark = SparkSession
.builder()
.appName("Spark SQL basic example")
.config("spark.some.config.option", "some-value")
.getOrCreate()
val df = spark.read.json("file:///d:/test_data/test.json")
import spark.implicits._
df.printSchema()
// SparkSQL
df.createOrReplaceTempView("people")
val sqlDF = spark.sql("SELECT * FROM people")
sqlDF.show()
数组比较
遇到一个奇怪的 bug,统计数据时发现某一天数据正常,重跑任务数据异常。像是随机化的结果,排查发现是 reduce 时,总是取第一个 object 的值。问题的原因是数组比较时总是 false。
Scala 中的数组比较有点奇怪,Array(1, 2) == Array(1, 2) 的结果是 false。需要使用 sameElements 方法来进行比较。
参考
https://spark.apache.org/docs/latest/sql-programming-guide.html