内存池是自己向OS请求的一大块内存,自己进行管理。
系统调用
我们先测试系统调用new/delete的用时。
#include <iostream>
#include <time.h>
using namespace std;
class TestClass
{
private:
char m_chBuf[4096];
};
timespec diff(timespec start, timespec end)
{
timespec temp;
temp.tv_sec = end.tv_sec-start.tv_sec;
temp.tv_nsec = end.tv_nsec-start.tv_nsec;
return temp;
}
int main()
{
timespec time1, time2;
clock_gettime(CLOCK_PROCESS_CPUTIME_ID, &time1);
for(unsigned int i=0; i< 0x5fffff; i++)
{
TestClass *p = new TestClass;
delete p;
}
clock_gettime(CLOCK_PROCESS_CPUTIME_ID, &time2);
cout<<diff(time1,time2).tv_sec<<":"<<diff(time1,time2).tv_nsec<<endl;
}
用时为604124400ns。系统的new是在堆上分配资源,每次执行都会分配然后销毁。
简单的内存池
#include <iostream>
#include <time.h>
using namespace std;
char buf[4100]; //已分配内存
class TestClass
{
public:
void* operator new(size_t)
{return (void*)buf;}
void operator delete(void* p){}
private:
char m_chBuf[4096];
};
int main()
{
timespec time1, time2;
clock_gettime(CLOCK_PROCESS_CPUTIME_ID, &time1);
for(unsigned int i=0; i< 0x5fffff; i++)
{
TestClass *p = new TestClass;
delete p;
}
clock_gettime(CLOCK_PROCESS_CPUTIME_ID, &time2);
cout<< diff(time1,time2).tv_sec<<":"<<diff(time1,time2).tv_nsec<< endl;
}
用时为39420791ns,后者比前者快20倍。
简单内存池在开始在全局/静态存储区分配资源,一直存在。每次重载的new调用只是返回了buf的地址,所以快。
MemPool定义
class CMemPool
{
private:
struct _Unit
{
struct _Unit *pPrev, *pNext;
};
void* m_pMemBlock;
struct _Unit* m_pFreeMemBlock;
struct _Unit* m_pAllocatedMemBlock;
unsigned long m_ulUnitSize; //一个单元的内存大小
unsigned long m_ulBlockSize; //整个内存池的内存大小
public:
CMemPool(unsigned long lUnitNum = 50, unsigned long lUnitSize = 1024);
~CMemPool();
void* Alloc(unsigned long ulSize, bool bUseMemPool = true);
void Free(void* p);
};
CMemPool定义了一个_Unit来管理链表,指针被包含在整个结构中,这种方式和内核中的链表写法很像。
m_pMemBlock指向分配的那块大小为m_ulBlockSize的大内存的地址。m_pMemBlock是线性的内存,我们把它用下列这种方式管理。
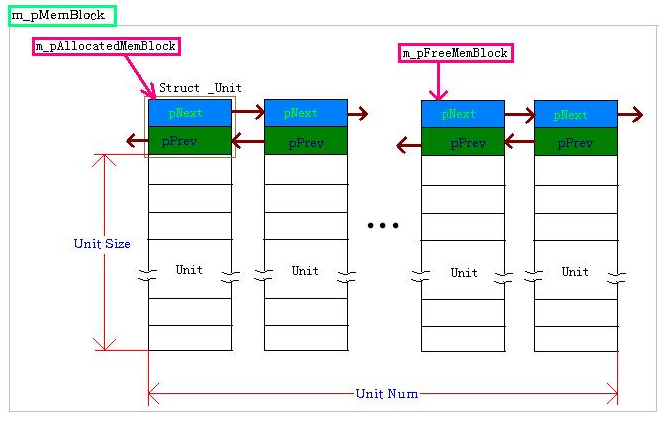
它被均分为lUnitNum个大小为m_ulUnitSize Byte的小内存块。每个块分为2部分:Unit链表管理头,真正进行存储的内存单元。
从图中可以看出m_ulBlockSize的计算方式为:
UnitNum * ( UnitSize + sizeof(Struct _Unit))
然后用双向链表连接所有的小块。m_pFreeMemBlock指向空闲的内存的起始位置,m_pAllocatedMemBlock指向已分配出去的内存的起始位置。
MemPool实现
CMemPool::CMemPool(unsigned long ulUnitNum, unsigned long ulUnitSize):
m_pMemBlock(NULL), m_pAllocatedMemBlock(NULL), m_pFreeMemBlock(NULL),
m_ulBlockSize(ulUnitNum * (ulUnitSize+sizeof(struct _Unit))),
m_ulUnitSize(ulUnitSize)
{
m_pMemBlock = malloc(m_ulBlockSize);
if(NULL != m_pMemBlock)
{
for(unsigned long i = 0; i<ulUnitNum; i++)
{
struct _Unit* pCurUnit=(struct _Unit*)((char*)m_pMemBlock\
+ i*(ulUnitSize+sizeof(struct _Unit)) );
pCurUnit->pPrev = NULL;
pCurUnit->pNext = m_pFreeMemBlock;
if(NULL != m_pFreeMemBlock)
{
m_pFreeMemBlock->pPrev = pCurUnit;
}
m_pFreeMemBlock = pCurUnit;
}
}
}
构造函数设置默认的小块数为50,每个小快大小为1024,最后用双向链表管理它们,m_pFreeMemBlock指向开始。
void* CMemPool::Alloc(unsigned long ulSize, bool bUseMemPool)
{
if(ulSize > m_ulUnitSize || false == bUseMemPool ||
NULL == m_pMemBlock || NULL == m_pFreeMemBlock)
{
cout << "System Call" << endl;
return malloc(ulSize);
}
struct _Unit *pCurUnit = m_pFreeMemBlock;
m_pFreeMemBlock = pCurUnit->pNext;
if(NULL != m_pFreeMemBlock)
{
m_pFreeMemBlock->pPrev = NULL;
}
pCurUnit->pNext = m_pAllocatedMemBlock;
if(NULL != m_pAllocatedMemBlock)
{
m_pAllocatedMemBlock->pPrev = pCurUnit;
}
m_pAllocatedMemBlock = pCurUnit;
cout << "Memory Pool" << endl;
return (void*)((char*)pCurUnit + sizeof(struct _Unit));
}
Alloc的作用是分配内存,返回分配的内存地址,注意加上Unit的大小是为了略过Unit管理头。实质是把m_pFreeMemBlock指向的free内存移动到m_pAllocatedMemBlock指向的已分配内存里。
每次分配时,m_pFreeMemBlock指针后移。pCurUnit从前面插入到m_pAllocatedMemBlock里。
void CMemPool::Free(void* p)
{
if(m_pMemBlock<p && p<(void*)((char*)m_pMemBlock + m_ulBlockSize))
{
//判断释放的内存是不是处于CMemPool
cout << "Memory Pool Free" << endl;
struct _Unit* pCurUnit = (struct _Unit*)((char*)p - \
sizeof(struct _Unit));
m_pAllocatedMemBlock = pCurUnit->pNext;
if(NULL != m_pAllocatedMemBlock)
{
m_pAllocatedMemBlock->pPrev == NULL;
}
pCurUnit->pNext = m_pFreeMemBlock;
if(NULL != m_pFreeMemBlock)
{
m_pFreeMemBlock->pPrev = pCurUnit;
}
m_pFreeMemBlock = pCurUnit;
}
else
{
free(p);
}
}
Free的作用是释放内存,实质是把m_pAllocatedMemBlock指向的已分配内存移动到m_pFreeMemBlock指向的free内存里。和Alloc的作用相反。
pCurUnit要减去struct _Unit是为了从存储单元得到管理头的位置,堆是向上生长的。
测试
#include "mempool.h"
#include <time.h>
CMemPool g_MemPool;
class CTestClass
{
public:
void *operator new(size_t); //重载运算符new
void operator delete(void *p);
private:
char m_chBuf[1000];
};
void *CTestClass::operator new(size_t uiSize)
{
return g_MemPool.Alloc(uiSize); //分配g_MemPool的内存给它
}
void CTestClass::operator delete(void *p)
{
g_MemPool.Free(p);
}
class CTestClass2
{
private:
char m_chBuf[1000];
};
timespec diff(timespec start, timespec end)
{
timespec temp;
temp.tv_sec = end.tv_sec-start.tv_sec;
temp.tv_nsec = end.tv_nsec-start.tv_nsec;
return temp;
}
int main()
{
timespec time1, time2;
for(int iTestCnt=1; iTestCnt<=10; iTestCnt++)
{
unsigned int i;
//使用内存池测试
clock_gettime(CLOCK_PROCESS_CPUTIME_ID, &time1);
for(i=0; i<100000*iTestCnt; i++)
{
CTestClass *p = new CTestClass;
delete p;
}
clock_gettime(CLOCK_PROCESS_CPUTIME_ID, &time2);
cout << "[ Repeat " << 100000*iTestCnt << " Times ]"
<< "Memory Pool Interval = " << diff(time1,time2).tv_nsec
<< "ns" << endl;
//使用系统调用测试
clock_gettime(CLOCK_PROCESS_CPUTIME_ID, &time1);
for(i=0; i<LOOP_TIMES; i++)
{
CTestClass2 *p = new CTestClass2;
delete p;
}
clock_gettime(CLOCK_PROCESS_CPUTIME_ID, &time2);
cout << "[ Repeat " << LOOP_TIMES << " Times ]"
<< "System Call Interval = " << diff(time1,time2).tv_nsec
<< "ns" << endl;
}
return 0;
}
结果
从下图可以看出,只有当程序频繁地用系统调用malloc/free或者new/delete分配内存时,内存池有价值。
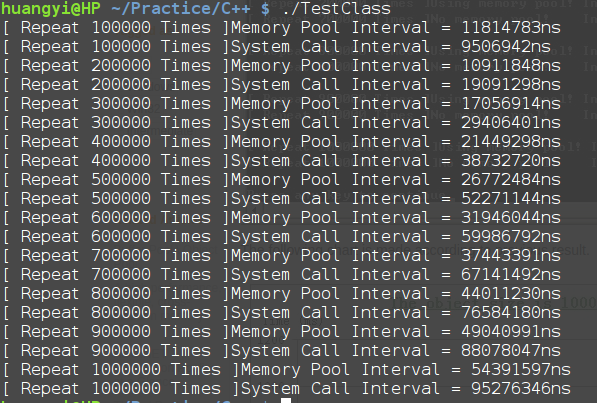
完整的实现存放在Github。
Reference
[1].http://www.codeproject.com/Articles/27487/Why-to-use-memory-pool-and-how-to-implement-it
[2].http://www.codeproject.com/Articles/15527/C-Memory-Pool
[3].http://blog.csdn.net/shawngucas/article/details/6574863