搜索引擎(Search Engine)是指根据一定的策略、运用计算机技术从互联网上搜集信息,在对信息进行组织和处理后,为用户提供检索服务。在日常生活中,可以看到 Google 等 Web 检索网站,还有邮件检索和专利检索等各种应用程序。
在自己写一个搜索引擎之前,需要先了解基本的原理和概念。比如分词,倒排索引,BM25 算法等。可以跟一下 Coursea 的公开课「Text Retrieval and Search Engines」,「自制搜索引擎」这本书从源码级别分析了搜索引擎的基本原理。
搜索引擎工作步骤分为这几步:
- 爬虫模块 Crawler 在网页上抓取感兴趣的网页数据存储为 Cached pages
- 索引构造器 Indexer 对 Cached pages 处理生成倒排索引(Inverted Index)
- 对查询词 Query 在倒排索引中查找对应的文档 Document
- 计算 Query 和 Document 的关联度,返回给用户 TopK 个结果
- 根据用户点击 TopK 的行为去修正用户查询的 Query,形成反馈闭环。
整个项目存放在 https://github.com/Huangtuzhi/just-search-engine。
组成组件
搜索引擎由下列 4 个组件构成。
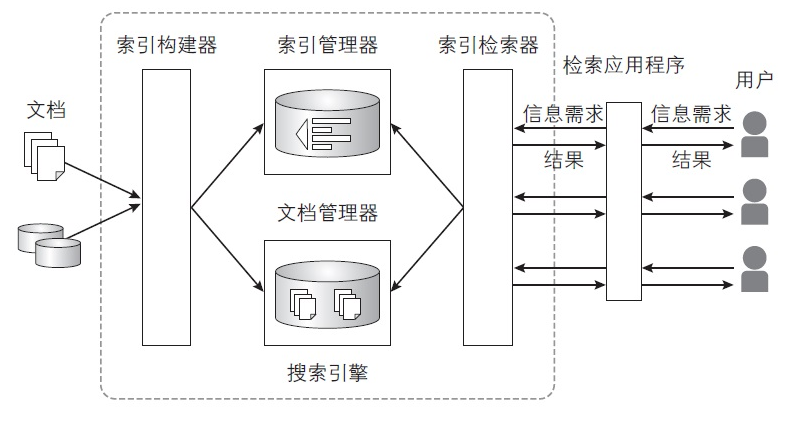
- 文档管理器(Document Manager)
- 索引构建器(Indexer)
- 索引管理器(Index Manager)
- 索引检索器(Index Searcher)
对应地,在项目结构中
├── just-search-engine
│ ├── documentManager.py # 文档管理器
│ ├── indexer.py # 索引构建器
│ ├── indexSearcher.py # 索引检索器
│ ├── README.md
│ ├── seedbase # 抓取 WIKI 的 set 对象持久化
│ ├── wiki-postings # 构建的倒排索引 map 对象持久化
│ ├── text
│ │ └── wiki-result # 对所有 MongoDB 中的文档统计的结果
收集文档
我们把抓取的一个网页叫做文档。以 Wikipedia 的网页作为数据源,这些网页数据都是非结构性的,很适合用 MongoDB 来进行存储。
MongoDB 需要依赖 mongodb-server 和 pymongo。安装好之后启动服务器
mongod --dbpath =/opt/mongodb-data --logpath=/opt/mongodb-data/mongodb.log
MongoDB 中有这些字段。
posting = {
"DocID": 22223,
"url": "https://en.wikipedia.org/wiki/Trout",
"content": "Trout is the common name for a number
of species of freshwater fish",
"keyword": "Trout"
}
content 存储网页的文字内容。DocID 自增,用来唯一标记文档,和倒排索引中的 DocID 对应,后面在 MongoDB 里也是用这个字段来检索出文字内容。
构建倒排索引
构建倒排索引只需要两步
- 对所有文档进行词频统计,将 <word, DocID, Freq> 写入到二级存储(文本)中
- 将文档按照 word 进行合并,构成倒排索引。使用字典存储索引,word 作为 key,[DocID, Freq] 组成的 list 作为 value。
{
"search":[[1, 3],[2, 1]],
"engine":[[2, 1]]
}
上面的索引表示:search 这个词在文档 1 中出现 3 次,在文档 2 中出现 1 次。
索引构建完毕之后,使用 pickle 库将索引持久化到二级存储中。
检索文档
检索 Query 一般是多个词元组成,如搜索 popular literature,需要把它分成两个词元
popular 和 literature 来处理。
假设 popular 在倒排索引中的 postings 为 [100, 200, 300]。
literature 在倒排索引中的 postings 为 [233, 300, 400]。
则包含两个词的文档为 300,可以将这个文档返回给用户。
这是在索引中检索一个词元的实现,它返回包含这个词元的 DocID 列表。
def retrive_word(self, word):
# 找出 DocID 对应的 url
manager = documentManager()
collection = manager.connect_mongo()
id_list = []
for word in self.word_dictionary[word]:
url = collection.find_one({"DocID": int(word[0])})["url"]
id_list.append(int(word[0]))
return id_list
文档排名——计算 TF-IDF
搜索引擎检索出文档之后,需要选择和查询最相关的文档返回给用户,因此需要对文档进行评估。一般有下列方法:
- TF-IDF 词频-逆文档频率
- 余弦相似度
- Okapi BM25
看一下 TF-IDF 的计算
def caculate_TFIDF(self, word):
score_dictionary = {}
for posting in self.word_dictionary[word]:
DocID = posting[0]
freq = posting[1]
idf = math.log(float(100) / len(self.word_dictionary[word]))
tf = 1 + math.log(int(freq)) if freq > 0 else 0
tfidf_score = tf * idf
score_dictionary[DocID] = tfidf_score
score = sorted(score_dictionary.iteritems(), key=lambda d:d[1], \
reverse = True)
print score
idf 是文档总数和该词元出现过文档总数的商。TF-IDF 作为衡量“词元在文档集合中是否特殊”的一个指标。
将算得的 TF-IDF 分数存储在字典中,最后按值进行排序。
文档排名——计算 Okapi BM25
TF-IDF 指标得到的是单个查询词的得分,若查询为一句话,可以使用 Okapi BM25 作为评分标准。
BM25 计算公式如下
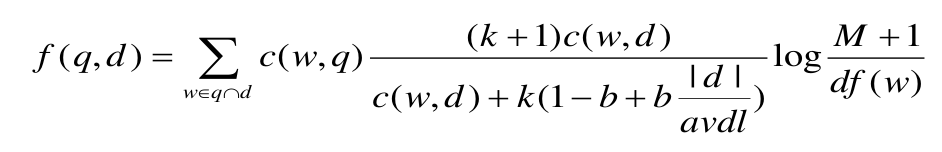
c(w,q) 代表在 Query 中出现某个词元的计数。一般当作 1 处理。
c(w,d) 代表在一个 Document 中出现某个词元的计数。
| k(1-b+b | d | /avdl) 是对文档长度进行归一化的处理。 |
当查询词为 popular literature,它会分别计算文档中 popular 和 literature 的得分,然后求和,作为这个文档对于查询词的相关性得分。