多任务可以用一个进程作为Master分配任务,其它进程作为Worker执行任务来实现。
这样可以把Master放在一台电脑上,Workers放在其他电脑上实现分布式。
Master节点
#!/usr/bin/env python
#taskmanager.py
import random, time, Queue
from multiprocessing.managers import BaseManager
task_queue = Queue.Queue()
result_queue = Queue.Queue()
class QueueManager(BaseManager):
pass
QueueManager.register('get_task_queue', callable=lambda: task_queue)
QueueManager.register('get_result_queue', callable=lambda: result_queue)
manager = QueueManager(address=('', 5000), authkey='abc')
manager.start()
task = manager.get_task_queue()
result = manager.get_result_queue()
for i in range(10):
n = random.randint(0, 10000)
print('Put task %d...' % n)
task.put(n)
print('Try get results...')
for i in range(10):
r = result.get(timeout=10)
print('Result: %s' %r)
manager.shutdown()
task_queue和result_queue是两个队列,分别存放任务和结果。multiprocessing库用来进行进程间通信(IPC),交换对象。
官网上有如下例子。
from multiprocessing import Process, Queuedef f(queue):
queue.put([42, None, 'hello'])
if __name__ == '__main__':
q = Queue()
p = Process(target=f, args=(q,))
p.start()
print q.get() # prints "[42, None, 'hello']"
p.join()
其中p是一个进程,还有一个主进程。可以看到列表[42, None, 'hello']从p进程传到了主进程中。
因为是分布式的环境,放入queue中的数据需要等待Workers机器运算处理后再进行读取,这样就需要对queue用QueueManager进行封装放到网络中。这是通过
QueueManager.register('get_task_queue', callable=lambda: task_queue)
实现的。我们给task_queue的网络调用接口取了一个名字叫get_task_queue,而result_queue的名字是get_result_queue,方便区分对哪个queue进行操作。
task.put(n)即是对task_queue进行写入数据,相当于分配任务。而result.get()即是等待workers处理后返回的结果。
Worker节点
#!/usr/bin/env
#task_worker.py
import time, sys, Queue
from multiprocessing.managers import BaseManager
class QueueManager(BaseManager):
pass
QueueManager.register('get_task_queue')
QueueManager.register('get_result_queue')
server_addr = '127.0.0.1'
print('Connect to server %s...' % server_addr)
m = QueueManager(address=(server_addr, 5000), authkey='abc')
m.connect()
task = m.get_task_queue()
result = m.get_result_queue()
for i in range(10):
try:
n = task.get(timeout=1)
print('run task %d * %d...' % (n, n))
r = '%d * %d = %d' % (n, n, n*n)
time.sleep(1)
result.put(r)
except Queue.Empty:
print('task queue is empty.')
print('worker exit.')
这里的QueueManager注册的名字必须和task_manager中的一样。注意到taskworker.py中根本没有创建Queue的代码,Queue对象存储在taskmanager.py进程中。对比上面的例子,可以看出Queue对象从另一个进程通过网络传递了过来。只不过这里的传递和网络通信由QueueManager完成。
task_worker的主要功能是将task_queue中分配的数据取出来进行平方运算然后放入到result_queue中。这样Master节点就能得到计算结果了。
测试结果
先运行task_manager.py如下
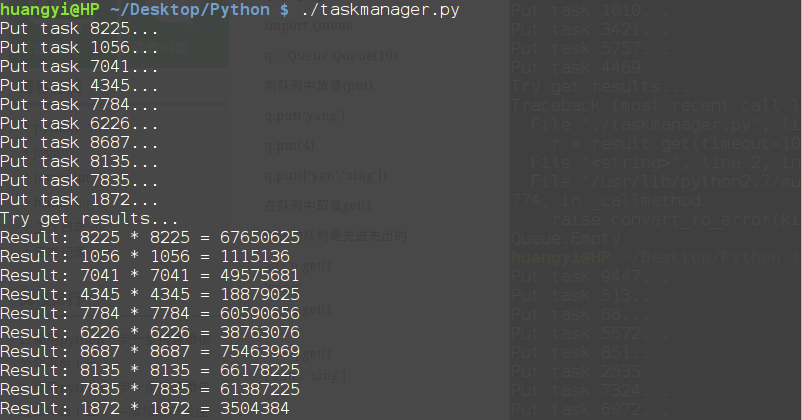
再运行task_worker.py如下
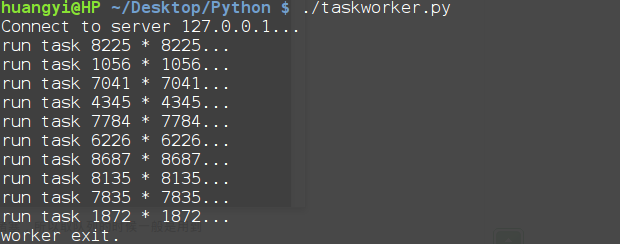
可以看到这里Workers对传过来的数据只是进行了简单的平方处理。这个简单的Manager/Worker模型有什么用?
其实这就是一个简单但真正的分布式计算,把代码稍加改造,启动多个worker,就可以把任务分布到几台甚至几十台机器上,比如把计算n*n的代码换成发送邮件,就实现了邮件队列的异步发送。或者可以利用多台机器求出N-皇后问题解的个数。
References
[1].http://blog.csdn.net/fireroll/article/details/38895485
[2].http://www.jb51.net/article/58004.htm
[3].https://docs.python.org/3/library/multiprocessing.html?highlight=queuemanager
[4].http://www.zhihu.com/question/22608820